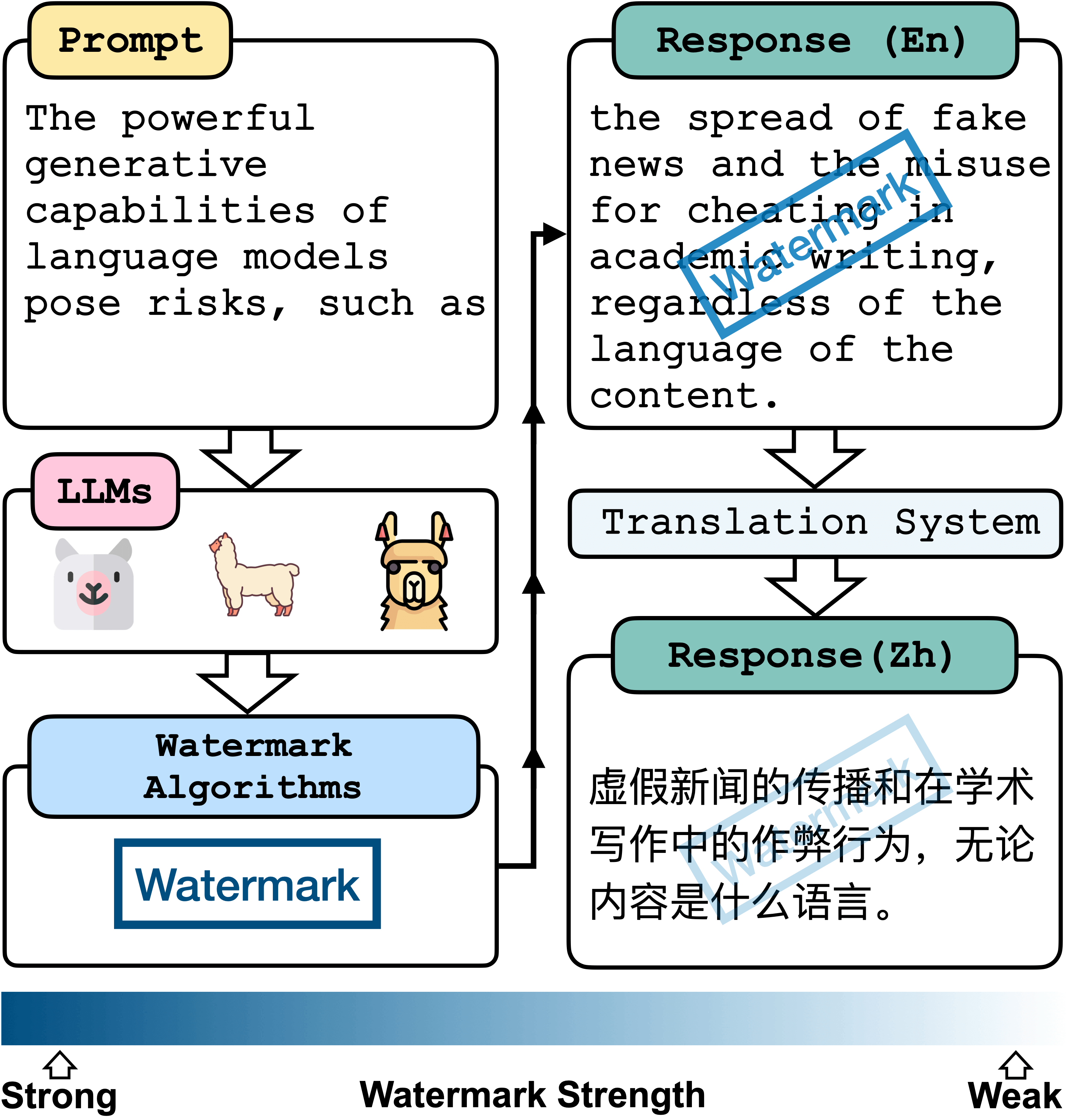
Text watermarking technology aims to tag and identify content produced by large language models (LLMs) to prevent misuse. However, can watermarks survive translation?
We complete a closed-loop study on this question:
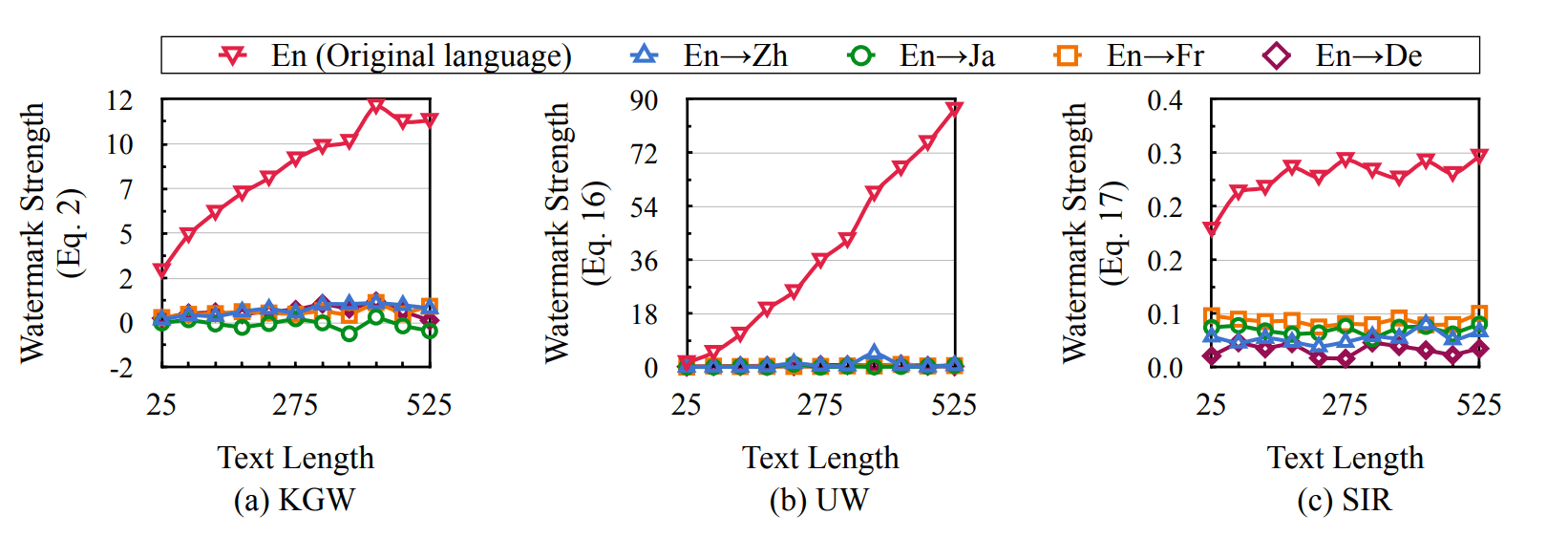
(1) Evaluation: We define the concept of cross-lingual consistency in text watermarking, which assesses the ability of text watermarks to maintain their effectiveness after being translated into other languages. Unfortunately, we find that current watermarking methods struggle to maintain their watermark strengths across different languages.
(2) Attack: We propose the cross-lingual watermark removal attack (CWRA). By wrapping the query to the LLM in a pivot language, it efficiently eliminates watermarks (AUC: 0.95 -> 0.67) without compromising performance.
(3) Defense: We analyze two key factors that contribute to the cross-lingual consistency in text watermarking and propose a potential defense method. Despite its limitations, it increases the AUC from 0.67 to 0.88 under CWRA.
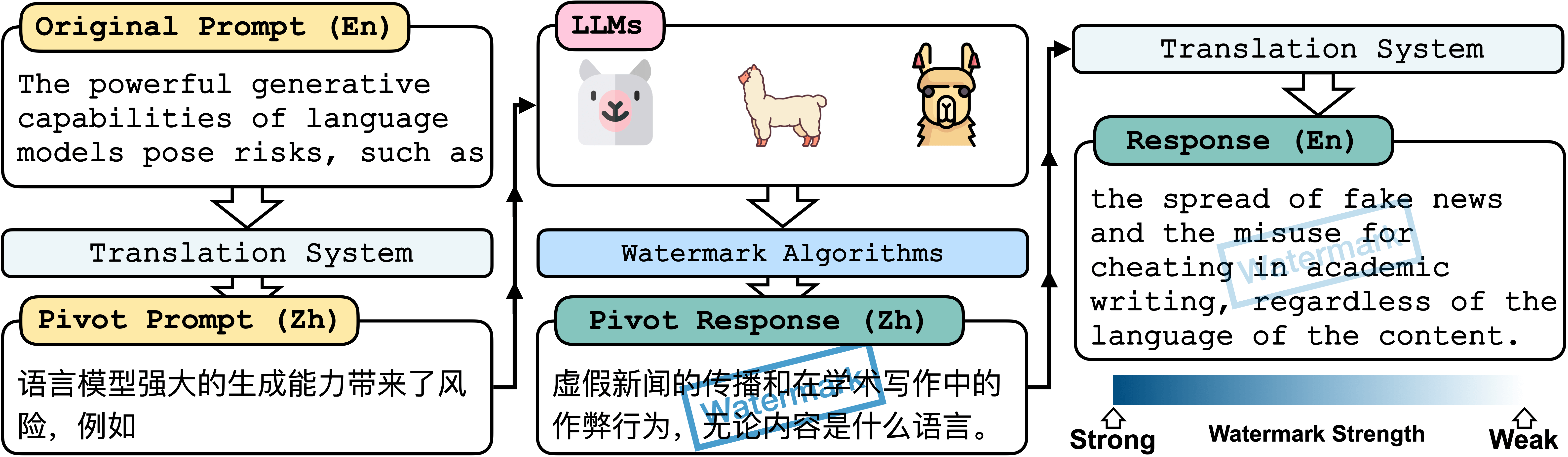
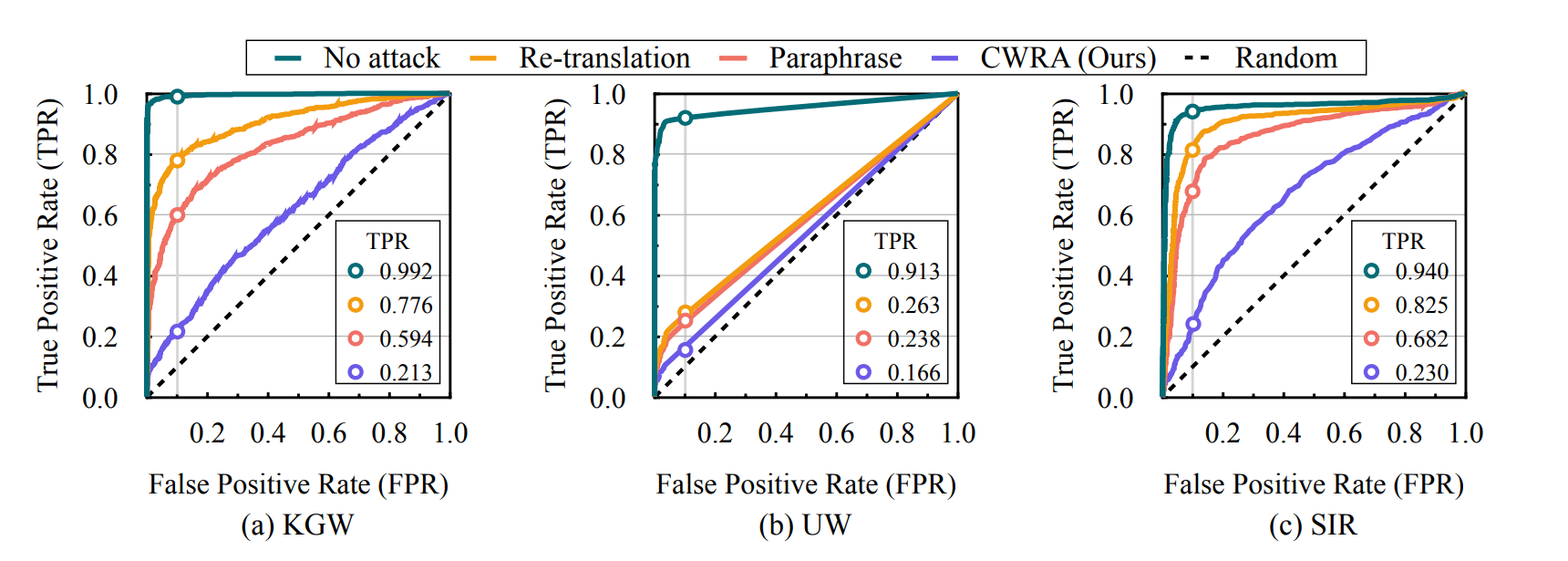
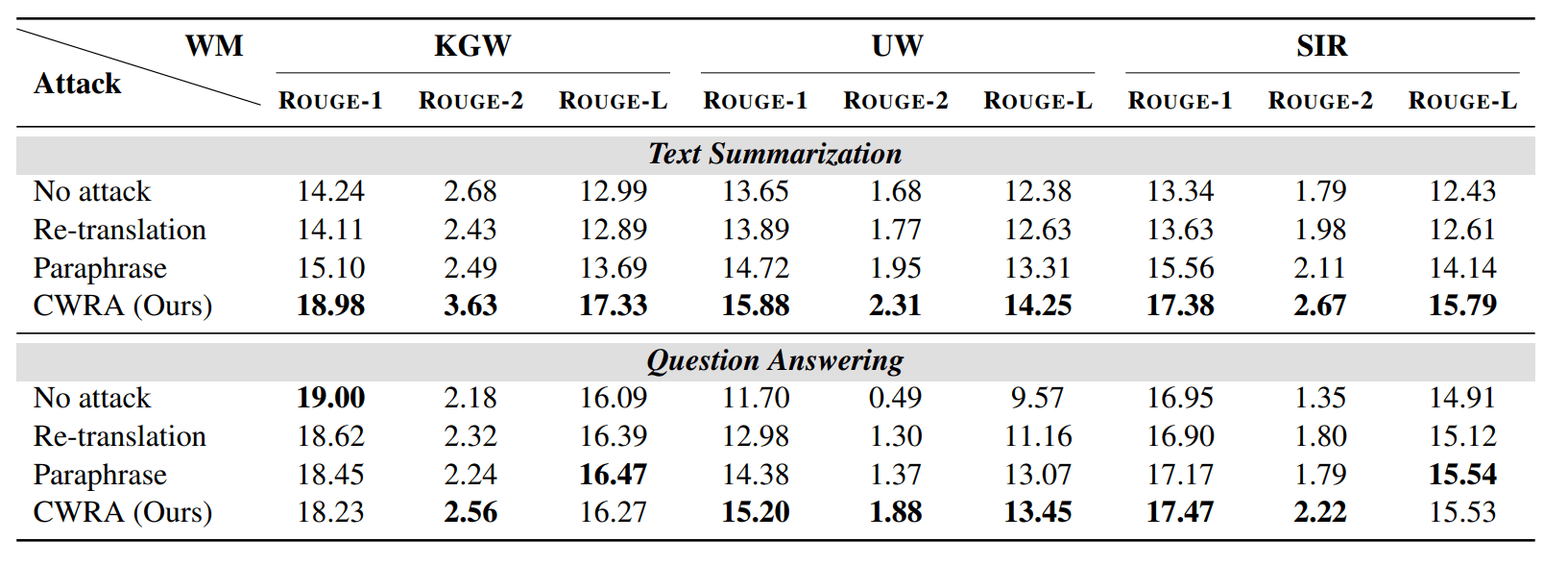
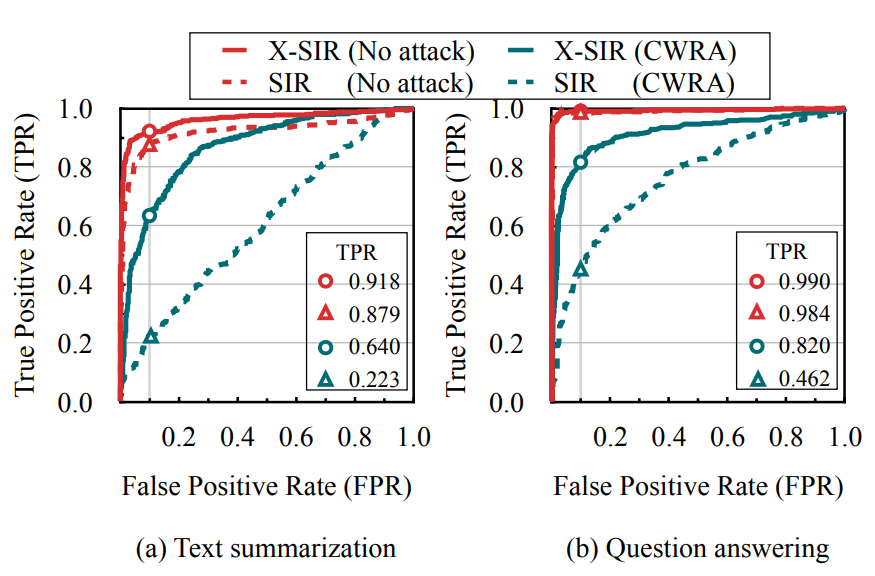
Fig 5: ROC curves of X-SIR and SIR under CWRA and no attack. |
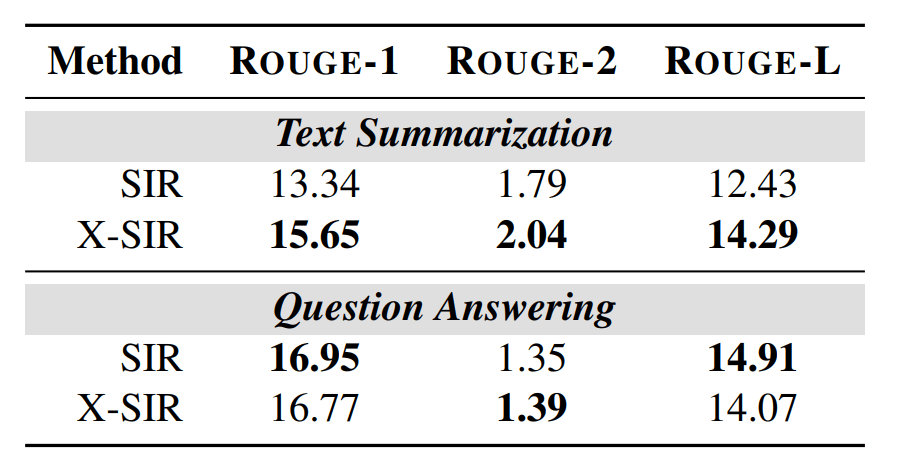
Fig 6: Text quality of X-SIR and SIR. |
@article{he2024can,
title={Can Watermarks Survive Translation? On the Cross-lingual Consistency of Text Watermark for Large Language Models},
author={He, Zhiwei and Zhou, Binglin and Hao, Hongkun and Liu, Aiwei and Wang, Xing and Tu, Zhaopeng and Zhang, Zhuosheng and Wang, Rui},
journal={arXiv preprint arXiv:2402.14007},
year={2024}
}[1] John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. ICML 2023.
[2] Zhengmian Hu, Lichang Chen, Xidong Wu, Yihan Wu, Hongyang Zhang, Heng Huang. Unbiased Watermark for Large Language Models. arXiv 2023.
[3] Aiwei Liu, Leyi Pan, Xuming Hu, Shiao Meng, Lijie Wen. A Semantic Invariant Robust Watermark for Large Language Models. ICLR 2024.